
Video Games Sales Data Analysis
Introduction
Have you ever wondered what is the most played video game in the last thirty years? How about which gaming platform is the most used in the last decade? Is Super Mario the most popular game ever? Or is Call of Duty the most appealing one in the last decade?
In this post, we are going to explore advanced data manipulation techniques that are typically used to translate raw data into insightful plots and charts — enabling you to answer these types of questions.
To perform this analysis, we will use the Python language, and we will explore two of the most important data analytics libraries: Pandas and Matplotlib.
Here i will just report the most important insights from the analysis. You can however check the source code to better understand the corresponding code source here. The data required for this analysis can be found at this stable link.
1. Data Manipulation and Cleaning
1.1 Data Ingestion
We read the file 'data/vgsales.csv' using the pandas read_csv() function, and store it into the variable data.
data = pd.read_csv('data/vgsales.csv')
We now check the overall composition of the dataset using the .info() method. The dataset contains sales information, divided by region, for different video games by year. This dataset is not the most updated, but it covers titles until 2016.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16598 entries, 0 to 16597
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Rank 16598 non-null int64
1 Name 16598 non-null object
2 Platform 16598 non-null object
3 Year 16327 non-null float64
4 Genre 16598 non-null object
5 Publisher 16540 non-null object
6 NA_Sales 16598 non-null float64
7 EU_Sales 16598 non-null float64
8 JP_Sales 16598 non-null float64
9 Other_Sales 16598 non-null float64
10 Global_Sales 16598 non-null float64
dtypes: float64(6), int64(1), object(4)
memory usage: 1.4+ MB
1.2 Data Cleaning
We clearly see there exists a few null values among both the Publisher and Year columns. The strategy here is to remove them.
Let us remove the null values using the pandas .dropna() method:
data.dropna(
subset=['Publisher', 'Year'],
how='any',
inplace=True
)
The dataset was generated at the end of the year 2016. Hence, each observation with an occurrence greater than or equal to 2017 must be considered as either corrupted or incorrect, and hence must be removed.
data = data.query('Year < 2017')
For more information on the query method, please check this post here.
1.3 Data Consistency
Before moving to a proper data analysis, we need to be sure the data is consistent. By consistency I mean an intrinsic characteristic of the data. For instance, the Publisher name might contain a typo, or sometimes a Publisher might be identified by several names.
To investigate this, let us check how Sony appears inside our dataset: we hence access to the Publisher column, which is of type object, and try to check the different names Sony is used for:
data[data['Publisher'].str.contains(
'sony',
case=False
)]['Publisher'].value_counts()
Sony Computer Entertainment 682
Sony Computer Entertainment Europe 15
Sony Online Entertainment 8
Sony Computer Entertainment America 3
Sony Music Entertainment 1
Name: Publisher, dtype: int64
Obviously, the Sony Publisher identifier is not homogeneously identified among observations. We might think of, say, transforming each single possibility to a more general one, say “Sony”, to reduce heterogeneity in our data.
To do this, we basically create a custom method, called merging_info_publisher, that should be called whenever we wish to perform such kind of cleaning on our data. You can find it in the aforementioned source code. Let us check now how "Sony" is mapped inside our dataset after the transformation:
data[data['Publisher'].str.contains(
'Sony'
)]['Publisher'].value_counts()
Sony 709
Name: Publisher, dtype: int64
Possibly, this pattern is repeated for different publishers as well. Here we identify a few Publishers that might have different labels inside the dataset, and we apply the merging_info_publisher method for each of them.
After the necessary transformation, let us check the absolute distribution of the top 20 Publishers in our dataset:
data['Publisher'].value_counts().head(20)
Electronic Arts 1341
Activision 996
Ubisoft 931
Namco 928
Konami 823
THQ 712
Sony 709
Nintendo 696
Sega 630
Take-Two Interactive 412
Capcom 376
Atari 347
Tecmo Koei 338
Square Enix 231
Warner Bros. Interactive Entertainment 217
Disney Interactive Studios 214
Midway Games 196
Eidos Interactive 196
505 Games 192
Microsoft Game Studios 189
Name: Publisher, dtype: int64
2. Total Games Released Each Year
We now want to know when the video game industry experienced a drastic development. Based on the number of games released each year, we might be able to find out when the video games boom happened. We store the distribution of video games releases by year inside the variable counter_df_by_year.
counter_df_by_year = filtered_data[
['Name', 'Year']
].drop_duplicates().groupby('Year').count()
counter_df_by_year.rename(
columns={'Name': 'Number of Games'},
inplace=True
)
Let us embed that dataframe into a graphical dimension, using matplotlib:
with plt.style.context('ggplot'):
fig, ax = plt.subplots(figsize=(10,8))
ax.plot(
counter_df_by_year.index,
counter_df_by_year['Number of Games'],
marker='d'
)
ax.set_xlabel('Year')
ax.set_ylabel('Number of Games')
ax.set_title('Evolution of Video Games Industry')
plt.show()
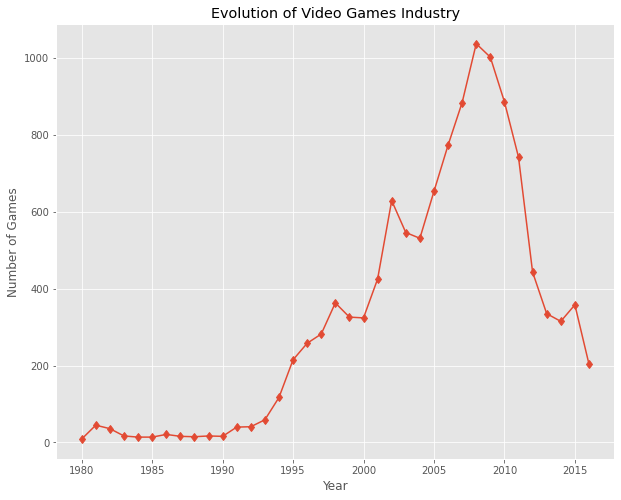
There was a significant boom in the late 2000s. Since then, the distinct number of release has shrunk possibly due to a more convergence to popular titles by both customers and developers.
3. Publisher Analysis with respect to Global Sales
Instead of considering absolute frequencies (with respect to the number of video games releases) of the top publishers, a better proxy is to consider the top publishers by Global Sales, identified by the columns "Global_sales".
The result is shown below here:

Nintendo is the most popular publisher (not surprisingly), followed by two other famous Publishers: Electronic Arts and Activision.
4. Understand the most popular Platform by Year
We now want to go further and try to see which Platform was the most popular for each Year. To do so, we again use a proxy the total Global Sales with respect to video games for each specific Platform.
However, this requires a little bit of data wrangling, and therefore we need to perform a few steps to be able to answer to this question. I kindly ask you to look at the source code for more details. I will just briefly explain what i do there:
- First of all, we count the number of video games by Platform using the
.groupby()method; - We then need two steps:
- pick the top 20 platform with respect to the column
Total Observations; - filter the data with respect to those Platforms.
- pick the top 20 platform with respect to the column
- The resulting dataframe, call it
filtered_data_top20, is then used to aggregate the data with respect to Global Sales using the pandas.pivot_table(). We would like to have, as columns, the platforms’ vendor and, as index, the year. Ideally, this is done like this:
pivoted_data = filtered_data_top20.pivot_table(
index='Year',
columns='Platform',
values='Global_Sales',
aggfunc='sum',
fill_value=0
)
- The next part is a little bit tricky: we now want to find the
Platformwhich has the top sales for each distinct year. To do that we employ theNumPymethodargsort()which basically allows to sort, for each row, the observations in ascending order. We then select the column names based on the sorting operation, so that in the first place we will find the platform with highest value with respect to the aggregated Global Sales.
The following table shows the tail of the yearly distribution of the most popular platforms during the last 40 years, obtained by following the above steps.
| Year | Platform | |
|---|---|---|
| 32 | 2012.0 | PS3 |
| 33 | 2013.0 | PS3 |
| 34 | 2014.0 | PS4 |
| 35 | 2015.0 | PS4 |
| 36 | 2016.0 | PS4 |
A natural question now is: which was the most popular game in each single year? To answer to this question, we can employ the code below here:
most_popular_games = pd.DataFrame()
for _, row in most_popular_platform_by_year.iterrows():
year = row['Year']
platform = row['Platform']
inner_df = filtered_data.query("Year == @year & Platform==@platform")
pivoted_table_year_platform = inner_df.pivot_table(
index = 'Year',
columns='Name',
values='Global_Sales',
aggfunc='sum',
fill_value=0
)
temp_col_max_value = pivoted_table_year_platform.max(axis=1).to_frame() # finds max value by row
temp_col_max_value.rename(columns={0:'Total sales (ML of units)'}, inplace=True)
temp_col_max = pivoted_table_year_platform.idxmax(axis=1).to_frame() # find the column with the greatest value on each row
temp_col_max.rename(columns={0:'Most Wanted Title'}, inplace=True)
merging_dfs = pd.concat([temp_col_max, temp_col_max_value], axis=1)
most_popular_games = most_popular_games.append(merging_dfs)
As we can see from the output shown here below, there are many famous titles: from Pac-Man to the Legend of Zelda in the 80’s; the 90’s are obviously identified by the Super Mario saga, but interestingly the most title for that particular decade was Gran Turismo: what a game! I still remember it. For that time, that game was absolutely a breakthrough! Also note that in 1995 Sony released Playstation 1, and not surprisingly games related to that platform were the most sold in the second half of the 90’s.
| Most Wanted Title | Total sells (ML of units) | |
|---|---|---|
| Year | ||
| 1980.0 | Asteroids | 4.31 |
| 1981.0 | Pitfall! | 4.50 |
| 1982.0 | Pac-Man | 7.81 |
| 1983.0 | Pitfall II: Lost Caverns | 1.31 |
| 1984.0 | Beamrider | 0.27 |
| 1985.0 | Ghostbusters | 0.45 |
| 1986.0 | Solaris | 0.37 |
| 1987.0 | Kung-Fu Master | 0.65 |
| 1988.0 | River Raid II | 0.51 |
| 1989.0 | Double Dragon | 0.47 |
| 1990.0 | Super Mario World | 20.61 |
| 1991.0 | The Legend of Zelda: A Link to the Past | 4.61 |
| 1992.0 | Super Mario Kart | 8.76 |
| 1993.0 | Super Mario All-Stars | 10.55 |
| 1994.0 | Donkey Kong Country | 9.30 |
| 1995.0 | Namco Museum Vol.1 | 3.84 |
| 1996.0 | Crash Bandicoot | 6.82 |
| 1997.0 | Gran Turismo | 10.95 |
| 1998.0 | Tekken 3 | 7.16 |
| 1999.0 | Gran Turismo 2 | 9.49 |
| 2000.0 | Final Fantasy IX | 5.30 |
| 2001.0 | Gran Turismo 3: A-Spec | 14.98 |
| 2002.0 | Grand Theft Auto: Vice City | 16.15 |
| 2003.0 | Need for Speed Underground | 7.20 |
| 2004.0 | Grand Theft Auto: San Andreas | 20.81 |
| 2005.0 | Madden NFL 06 | 4.91 |
| 2006.0 | Wii Sports | 82.74 |
| 2007.0 | Wii Fit | 22.72 |
| 2008.0 | Mario Kart Wii | 35.82 |
| 2009.0 | Wii Sports Resort | 33.00 |
| 2010.0 | Kinect Adventures! | 21.82 |
| 2011.0 | Call of Duty: Modern Warfare 3 | 13.46 |
| 2012.0 | Call of Duty: Black Ops II | 14.03 |
| 2013.0 | Grand Theft Auto V | 21.40 |
| 2014.0 | Grand Theft Auto V | 11.98 |
| 2015.0 | Call of Duty: Black Ops 3 | 14.24 |
| 2016.0 | FIFA 17 | 4.77 |
Also, moving to modern times we see that GTA V was quite a popular game, and without any surprise the popular Call of Duty: Black Ops 3, which was a very good game from Activision.
Given the above results, we can perform a little bit of data manipulation, and we can get the following result, which shows the most sold Title by Platform. Interestngly, GTA V was the most sold title for both PS3 and PS4: unbelivable!
| Most Wanted Title | Total sells (ML of units) | |
|---|---|---|
| Platform | ||
| 2600 | Solaris | 7.81 |
| PS | Tekken 3 | 10.95 |
| PS2 | Need for Speed Underground | 20.81 |
| PS3 | Grand Theft Auto V | 21.40 |
| PS4 | Grand Theft Auto V | 14.24 |
| SNES | The Legend of Zelda: A Link to the Past | 20.61 |
| Wii | Wii Sports Resort | 82.74 |
| X360 | Kinect Adventures! | 21.82 |
Surprisingly none of the Super Marios is mentioned in this list! Hence, we can conclude woth the following analysis: which were the most sold videogames ever?
We are interesting in investigating which were the most sold titles in the last 40 years. To do so, we employ the .groupby() method, and store the result into the most_wanted_vg variable.
most_wanted_vg = filtered_data_top20[
['Name', 'Global_Sales']
].groupby('Global_Sales').sum()
most_wanted_vg.sort_values(
by='Global_Sales',
ascending=False
).head(10)
The result is shown here below:
| Name | |
|---|---|
| Global_Sales | |
| 82.74 | Wii Sports |
| 35.82 | Mario Kart Wii |
| 33.00 | Wii Sports Resort |
| 30.01 | New Super Mario Bros. |
| 29.02 | Wii Play |
| 28.62 | New Super Mario Bros. Wii |
| 24.76 | Nintendogs |
| 23.42 | Mario Kart DS |
| 22.72 | Wii Fit |
| 22.00 | Wii Fit Plus |
It looks like the Nintendo games were the most sold! The Wii Sports was such a huge success for Nintendo. The classic Mario games, however, own 4 of Top 10 most popular games.
Conclusions
I hope you have enjoyed this analysis: it shows how pandas and Matplotlib are important to help you in the interpretability of the raw data.
If you want to replicate the results seen in this post, please check the source code here.
If you have enjoyed this post, please do not forget to star the repository where the source code is placed. See you in the next post!